



分享:高通量自动流程集成计算与数据管理智能平台及其在合金设计中的应用

王冠杰1,2, 李开旗1,2, 彭力宇1,2, 张壹铭1,2, 周健1,2, 孙志梅
1.
2.
材料研发模式经历了经验主导的第一范式、理论模型主导的第二范式和计算模拟主导的第三范式,如今正处于数据驱动的第四范式。为加速新材料的设计与研发,发展基于材料数据库和人工智能算法的高通量自动集成计算和数据挖掘算法变得至关重要。本文介绍了作者团队自主开发的分布式高通量自动流程集成计算和数据管理智能平台ALKEMIE2.0 (Artificial Learning and Knowledge Enhanced Materials Informatics Engineering 2.0),该平台基于AMDIV设计理念,包含了自动化、模块化、数据库、人工智能和可视化流程等5个适用于数据驱动的材料研发模式核心要素。概括来说,ALKEMIE2.0以模块化的方式集成了多个不同尺度的计算模拟软件;其高通量自动纠错流程可实现从建模、运行到数据分析,全程自动无人工干预;支持单用户不低于104量级的并发高通量自动计算模拟。进一步而言,ALKEMIE2.0具有强大的可移植性和可扩展性,目前已部署在国家超算天津中心,基于多类型材料数据库结合超算强大的计算能力使得人工智能算法在新材料设计与研发中得以快速的应用和实践。更重要的是,ALKEMIE2.0设计了用户友好的可视化操作界面,使得结构建模、工作流计算逻辑、数据分析和机器学习模型具有更高的透明性和更强的可操作性,且适用于对材料计算模拟掌握程度从初级到专业的所有材料研究人员。最后,通过多平台部署和高通量筛选二元铝合金2个算例详细展示了ALKEMIE2.0的主要特色及功能。
关键词:
近年来,美国、欧洲和日本等国家的科研人员相继开发了一系列的高通量计算软件、材料数据库和材料人工智能算法。其中高通量计算软件包括美国伯克利大学劳伦斯实验室开发的Materials Project[6],其包含Pymatgen[7]、FireWorks[8]、Custodian和Atomate[9]等一系列材料计算分析软件;美国杜克大学开发的AFLOWπ[10];瑞士洛桑理工大学Marvel项目组开发的高通量计算引擎AiiDA[11];丹麦大学开发的ASE (Atom Simulation Environment)[12]等。材料数据库包含ICSD (Inorganic Crystal Structure Database)[13]、COD (Crystallography Open Database)[14]、Materials Project[6]、AFLOW-Lib (Automatic Flow Lib)[15]、Materials Cloud (Web Database of AiiDA)[11]、OQMD (Open Quantum Materials Database)[16]、Materials Web、NOMAD (Novel Materials Discovery)[17]、日本国立材料科学研究所(NIMS)数据库和MatNavi检索系统等一系列大型材料数据库。人工智能算法分为通用的Scikit-learn[18]、TensorFlow[19]和Pytorch[20]人工智能框架和针对材料性能开发的专用人工智能算法,该算法包括针对材料描述符的SISSO[21]、预测结构性能的AFLOW-ML[22]、适用于材料数据挖掘的MatMiner[23]等。
尽管目前国际上涌现出众多适用于新材料研发的软件,但是大部分软件只能满足材料设计研发三要素中的1个或2个,无法完成从高通量自动计算、构建材料数据库和基于人工智能进行数据挖掘的完整流程的自动化运行。因此,本团队于2017年基于Python和C++开发了集材料基因工程三要素(高通量自动计算流程、材料大数据和人工智能算法)于一体的可视化平台ALKEMIE (Artificial Learning and Knowledge Enhanced Materials Informatics Engineering)[24],其最初版本只具有基础第一性原理计算和简单的数据分析及可视化功能,且初期架构仅适用于点对点式的“客户端-服务器”模式,无法满足大用户量和高并发式的计算需求。近年来,随着大规模并行计算服务器和高通量计算算法的革新,材料数据的大量积累以及人工智能技术的日趋成熟,为了实现将材料高通量自动计算流程、材料数据库和材料人工智能算法3部分有机结合,本团队基于全新的理念设计和架构研发了分布式的高通量自动流程集成计算及数据管理智能平台ALKEMIE2.0。
本文首先介绍ALKEMIE2.0的设计理念、系统架构、平台概况和功能特色;其次介绍该平台用到的关键技术,包括高通量自动流程与智能纠错、材料多类型数据库和人工智能机器学习算法;最后结合多平台部署和高通量筛选力学性能和电学性能优异的二元铝合金2个算例验证ALKEMIE2.0的主要功能特色。
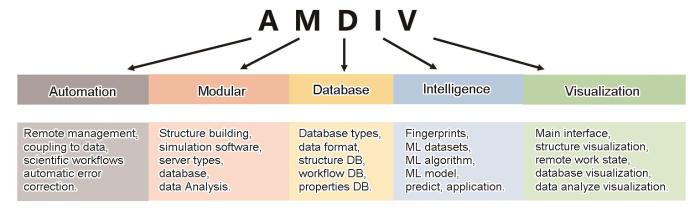
ALKEMIE2.0的设计理念如图1所示,主要分为以下5个方面。
图1 ALKEMIE2.0平台的AMDIV设计理念
Fig.1 The AMDIV design philosophy of ALKEMIE2.0 platform (ALKEMIE—Artificial Learning and Knowledge Enhanced Materials Informatics Engineering, DB—database, ML—machine learning)
材料基因工程的基本理念是变革传统的“试错法”材料研究模式,发展高效和协同创新的新型材料研发模式,使得新材料的研发周期缩短一半,研发成本降低一半,因此整个平台的自动化运行必不可少,这里的自动化主要包含以下4个方面:
① 自动化远程集群连接和管理。大多数材料计算模拟分析软件和大型科学计算集群都基于Linux系统搭建,这使得非计算机背景的材料科研人员需要学习Linux操作系统,编译安装软件和集群作业管理等非科研相关的知识,无法专注于本身的科研问题。ALKEMIE2.0通过在服务端开启守护进程(daemon)的方式自动监测科研人员的连接请求(request),并通过通用接口(API)和可视化窗口自动管理远程服务器运行状态,且该方式兼容不同的操作环境、计算软件和作业管理系统。
② 自动化数据耦合。常用的材料计算模拟软件大致可以分为建模调参、多任务计算和结果存储与分析3个步骤。因此如何实现每个步骤间自动的数据传递至关重要。ALKEMIE2.0通过定义数据管道和数据流(data-flow),为每个步骤定义通用的输入和输出信号来实现数据的实时交互。
③ 科学工作流。对于仅包含单个子任务的计算任务,可以通过常用的循环遍历实现自动化运行。但是对于包含多个输入,多个参数传递和子任务的复杂任务而言,实现高通量自动运行则变得非常困难。不仅需要判断输入参数的有效性,还需要解决多个子任务间的嵌套关系以及计算结果的存储和重复利用等问题。ALKEMIE2.0通过定义科学工作流的方式可以很容易地解决多任务的嵌套关系以及数据的存储和重复利用问题,研究人员只需要根据给定的模板输入计算参数即可自动化运行,具体科学工作流的设计逻辑在2.1节详细阐述。
④ 自动纠错。在自动化的科学工作流运行过程中,难免会有计算参数或硬件的错误,如何在海量的计算数据中精准定位错误并加以修正后再次重新计算对于自动流程至关重要。ALKEMIE2.0收集并深入分析了第一原理计算过程中常见的错误,并构建了一系列基于Python的ErrorFix错误收集器用于制定对应参数调整策略并重新提交计算从而实现自动纠错功能。
目前,材料计算模拟软件有数百种之多,一方面,不同的计算软件有不同的参数输入要求,不同的输出格式,且互不兼容。计算模拟的体系大小横跨电子、原子、微观、介观和宏观等多个尺度,模拟时长从飞秒、毫秒到几小时甚至数天不等;另一方面,根据不同的材料性能需求,材料计算模拟所侧重的结果输出和材料数据库也不尽相同。因此,为了兼容不同的计算模拟软件,不同的读写格式、不同的计算尺度和时间跨度,以及不同的数据库类型,模块化编程变得至关重要。ALKEMIE2.0从底层的系统架构,到顶层具有特定功能的可视化窗口都基于模块化实现,不同的模块之间通过API实现相互通信。举例而言,我们将高通量自动计算所需要的繁琐流程细分为5个不同的模块(结构建模模块、计算模拟软件模块、远程服务器模块、数据库模块、和数据分析模块),并为每个模块提供详细的功能扩展接口,用户仅需要根据自己的计算模拟需求以搭积木的方式将不同的模块化组合即可实现高通量自动计算。
随着计算模拟数据量的日益增长,以传统的文件夹格式保存材料数据已经成为效率极低的方式。一方面,文件夹无法查看保存的具体材料信息;另一方面,数据检索和查询非常困难。对于高通量自动计算产生的海量数据,格式化的存储极为重要。因此,基于欧洲科学家提出的FAIR Data的原则,数据应该满足可发现、可获取、可互操作和可再利用这4个特性[17]。在ALKEMIE2.0的设计理念中,材料数据库被分为3大类:结构数据库、工作流数据库和性能结果数据库。结构数据库和工作流数据库均采用非关系型数据库(MongoDB);而性能结果数据库为了兼顾高效的数值查询和存储,采用关系型(MySQL)数据库作为基础类型;除此之外,对于数据量较大的性能结果,比如态密度或者能带数据,采用MongoDB的GRIDF格式存储。
人工智能是目前各个学科的热门研究领域,但是如何将人工智能的方法有效地应用到材料计算模拟中还需深入探索。人工智能方法无论是针对分类问题还是连续问题,基本都依赖于对数值或者矩阵的运算,但是如何将三维的材料结构信息有效转化为人工智能可以识别的数值信息是至关重要的步骤。因此,ALKEMIE2.0为了使不同的人工智能方法在材料中得以应用,将实现方法分为以下6个部分:
① 指纹函数:用来将三维的材料结构信息或者材料性能数据转化为人工智能可以识别的数值数据;
② 材料数据集:定义可用于机器学习的数据的训练集、测试集、验证集以及特征值和标签值;
③ 机器学习算法:集成机器学习常用的收敛算法(梯度下降算法、提升(boosting)算法、Newton和拟Newton算法等[25]),并提供可用于算法拓展的通用接口;
④ 机器学习模型:集成随机森林,K近邻、神经网络、卷积神经网络、循环神经网络、胶囊神经网络、图神经网络等模型[26],并提供可用于自定义模型的通用接口;
⑤ 机器学习预测:根据机器学习模型,定义如何在测试集上验证模型的准确性;
⑥ 模型应用:定义基于机器学习模型获取的材料性能的接口,可以将机器学习的性能预测值作为材料计算模拟的一个步骤被其他计算软件或实际应用程序调用。
科研人员通常希望将更多的精力集中于如何构建合理的初始构型、创建高效的自动科学工作流和分析高质量的计算结果,而不是将时间浪费在命令式的软件学习和使用上。因此,ALKEMIE2.0基于PyQT设计了一套用户友好的可视化操作界面,既可以使材料计算模拟的初学者快速使用,也可以使熟练掌握计算模拟的专业科研人员快速进行功能拓展,其主要包含以下4个部分:
① 可视化主界面:软件的登录、服务器连接、高通量流程的模块化构建、数据传递等都以透明的可视化方式展现。
② 结构建模可视化:大部分计算软件都没有结构信息的可视化功能,用户将大多时间浪费在构建模型和将模型从服务器拷贝到本地再可视化上。本团队为ALKEMIE2.0开发了Builder和Viewer插件,将结构建模、结构信息的可视化与自动计算通过数据流进行无缝连接。
③ 远程工作状态可视化:远程服务器及任务的运行状态通常都是基于Linux的命令行查看,操作起来非常困难且信息不够直观。ALKEMIE2.0通过Job State可视化部分,实时展示远程计算机的作业状态并查看每个任务详细信息。
④ 数据分析可视化:通常的数据分析及后处理都依赖于将计算结果从远程拷贝到本地,并依赖第三方软件进行画图和分析,对于高通量数据多张数据图的绘制既繁琐又容易出错。ALKEMIE2.0在设计之初基于上述的计算结果数据库,通过强大的Python科学计算与画图软件包matplotlib和seaborn[27],开发了一系列自动统计分析、材料态密度分析、能带分析、声子谱和声子密度分析的模块,对于高通量任务,可以同时自动绘制并保存多张材料性能图片。
基于上述的AMDIV设计理念,ALKEMIE2.0平台架构如图2所示,主要分为可视化(GUI)、服务器(Server)、数据库(Database)、内核(Core)和插件(Plugin) 5个主体模块:
图2 ALKEMIE2.0系统架构
Fig.2 The architecture of ALKEMIE2.0 (GUI—graphical user interface, SSH—secure shell, AI—artificial intelligence, DOS—density of state, DFT—discrete Fourier transform, I/O—imput and output)
(1) 可视化模块(ALKEMIE-GUI,图2红色部分):用户与后台程序和远程服务器的交互界面,主要分为用户登录界面、功能界面和命令行连接界面。登录界面主要用于用户登录与服务器切换功能;功能界面主要用于ALKEMIE2.0每个核心功能的可视化部分,主要包括人工智能可视化、工作流可视化、数据可视化、结构建模可视化和工作状态可视化等。命令行界面属于开发人员界面,用于软件调试和服务器模块测试。
(2) 服务器模块(ALKEMIE-Server,图2灰色部分):ALKEMIE2.0的服务器主要分为2大类,一类是用于为用户提供密码验证、数据安全传输和管理操作权限的登录服务器,一类是可以自主选择的科学计算服务器。登录服务器由ALKEMIE2.0开发人员统一管理;计算服务器则详细定义了每个用户可操作的节点数量、可计算的核数、计算时间、计算所用CPU信息以及计算目录等,任何超级计算中心在部署了ALKEMIE2.0服务端后均可以作为智能计算服务器。
(3) 数据库模块(ALKEMIE-Database,图2紫色部分):多类型数据库为整个软件的稳定运行提供数据检索、查询和存储服务,并为用户提供数据安全保障。数据库格式主要分为关系型数据库、非关系型数据库,以及MongoDB中用于保存大文件的GridFS数据集。数据库类型主要包括用户数据库、材料结构数据库、工作流数据库、材料性能与计算结果数据库、人工智能数据库和论文数据库等。
(4) 内核模块(ALKEMIE-Core,图2蓝色部分):内核模块是ALKEMIE2.0核心功能按照一定的运算逻辑集成的模块。其细分为结构建模、计算引擎、自动纠错、科学工作流、远程工作管理、数据分析和人工智能等不同的子模块。子模块可以通过主模块的API访问界面、数据库、服务器和插件等扩展功能,也可以通过Python的import模块进行子模块间的相互通信与功能调用。
(5) 插件模块(ALKEMIE-Plugin,图2绿色部分):插件模块主要为上述4个模块提供拓展功能的支持。插件模块为每个主模块定义了通用接口,该接口指定了需要添加的具体属性和方法,用户可以通过继承该接口来实现扩展功能。其中数据库模块可扩展功能包括数据格式、数据库键值和数据类型;内核模块中,人工智能子模块可扩展功能包括适用于人工智能的数据生成器、机器学习模型、超参数自动测试方法、模型预测方式和模型回调函数等;计算引擎子模块可扩展功能包括第一性原理计算、热动力学、分子动力学、相图相场模拟和多尺度模拟软件的扩展;作业管理子模块可扩展功能包括PBS、SLURM和LSF作业管理系统等;数据分析子模块可扩展功能包括数据分析方法、画图方法和输出格式等;工作流子模块可扩展功能包含不同计算模拟软件具体的任务类型;建模子模块可扩展功能包括掺杂、晶界、异质结等;服务器模块可扩展功能包括将个人服务器作为ALKEMIE2.0计算服务器的方法;可视化模块可扩展功能主要包含如何将另外4个模块定义的实际功能通过可视化窗口展示出来,并添加到程序主界面中。通过插件模式,ALKEMIE2.0可以将任何复杂的材料计算流程转变为可视化的具有高通量数据读写功能的科学计算工作流。不同模块的插件具体扩展方法,可参见ALKEMIE2.0开发文档。
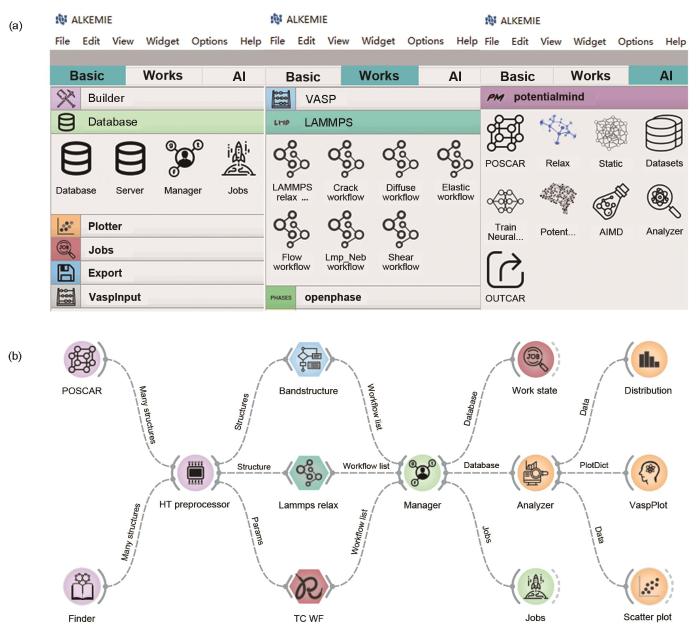
ALKEMIE2.0 平台概况及可视化工作流如图3所示。该平台主界面分为功能选择区(图3a)和工作区(图3b) 2部分。详细来说,功能选择区根据功能类别主要分为3类,每个类别在工作区以不同的控件形状显示,如图3所示,分别为以圆形控件为代表的与工作流配置相关的基础(Basic)类,以六边形控件为代表的与计算模拟科学工作流相关的工作(Works)类,以及以正方形控件为代表的与机器学习和数据挖掘相关的人工智能(AI)类。进一步而言,每个大类包含了具有不同功能的多个子类,每个子类又进一步包含了具有实际运行功能的多个控件。其中基础类包含了建模、数据库、画图、远程工作管理和输出等相关的子类;工作类包含了第一性原理计算软件VASP[28]、Quantum Espresso[29,30]、Abinit[31]、分子动力学计算软件LAMMPS[32]、相图相场计算软件OpenPhase[33]、OpenCalphd[34]、热力学计算软件Gibbs[35]和动力学计算软件动态Monte Carol (KMC)[36]等子类;人工智能类包含了机器学习模型和适用于分子动力学模拟的深度势函数PotentialMind 2个子类。在功能选择区域点击具有某个功能的按钮,会在工作区出现对应形状和颜色的控件,多个控件之间可通过数据管道进行数据交互,将不同功能的控件通过数据管道以不同的顺序首尾相连来构建具有高通量功能的自动工作流程。
图3 ALKEMIE2.0平台概况及可视化工作流
(a) the modular (b) work area and workflows of ALKEMIE2.0
Fig.3 The outline of ALKEMIE2.0 platform (AIMD—abinitio molecular dynamics, HT—high-throughput, TC WF—Curie temperature workflow)
ALKEMIE2.0主要包含9个方面的特色功能:
(1) 高通量:ALKEMIE2.0可以实现单用户超过104量级的并发高通量计算任务。
(2) 自动化:该平台的科学工作流从建模、计算到数据分析全程自动运行无需人工干预,运行过程可以采用默认参数,也可采用用户自定义参数。
(3) 可视化:该平台基于PyQT设计了用户友好的可视化界面,使得高通量内部的工作流程和数据传递方式更加透明,操作更加便捷,方便具有不同材料知识背景的用户使用。
(4) 工作流:该平台开发设计了适用于多种计算软件的科学工作流,使用户得以从繁琐甚至困难的计算流程中解放,极大提高了计算和工作效率。
(5) 数据库:构建了多种类型的材料数据库,包括材料结构数据库、工作流数据库、材料性质数据库、论文数据库、适用于机器学习的结构描述符数据库等。
(6) 机器学习:该平台基于Scikit-learn、PyTorch和TensorFlow等多种通用的机器学习工具开发了适用于材料结构能量预测、原子受力预测和带隙预测的模型,并为模型的进一步开发和应用定制了统一的底层接口。
(7) 插件模式(可扩展性):该平台支持以插件模式集成添加多尺度不同功能的计算模块,目前已添加多个不同尺度的计算软件,包含第一原理计算软件VASP、Quantum Espresso、Abinit;分子动力学软件LAMMPS;热力学计算软件Gibbs;相图相场计算软件OpenPhase和OpenCalphd等。其中部分软件仅提供算例功能,未来将进一步完善丰富。
(8) 可移植:适用于Windows、Linux、Mac OS等多个操作系统。
(9) 跨尺度:集成了第一原理计算(VASP、Quantum Espresso和Abinit)、分子动力学模拟(LAMMPS)、热力学计算(GIBBS2)、动态Monte Carlo模拟(KMC)和介观尺度相图相场模拟(OpenCalphd和OpenPhase)的相关软件,可通过参数传递的方式实现单一尺度及跨尺度计算功能。进一步,通过自主开发的神经网络势函数PotentialMind可以实现电子尺度(第一性原理)和原子尺度(分子动力学)的基于机器学习势函数的跨尺度计算模拟。
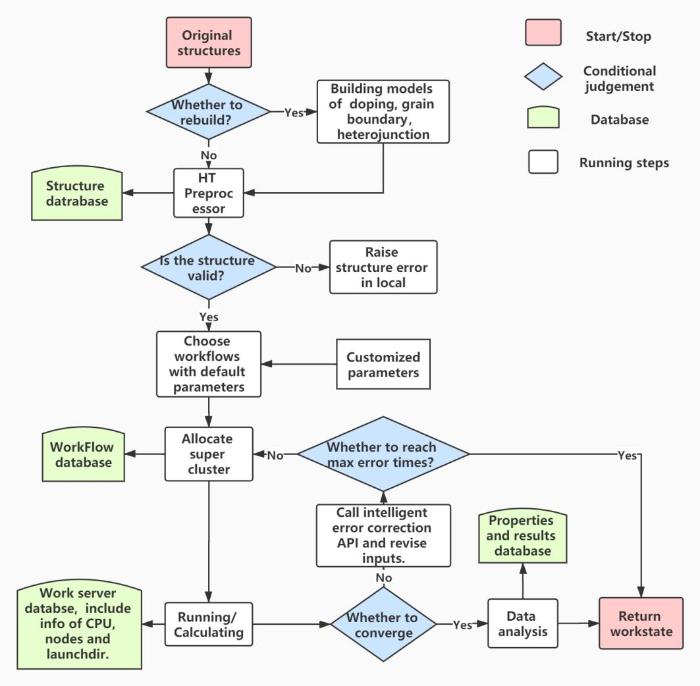
高通量自动计算流程分为高通量和自动化2个方面。高通量不等价于传统意义上大批量循环作业,基于材料基因工程的高通量计算主要包含高通量建模、高通量科学工作流、高性能远程计算、高通量数据存储、高通量数据分析以及智能纠错等多个方面。而自动化就是将上述所有的步骤通过程序化的方式自动实现,对于使用者而言,仅需要提供输入数据,可以自动完成上述高通量计算的所有步骤并获得最终目标结果。ALKEMIE2.0中高通量自动计算与智能纠错的流程如图4所示。首先用户输入初始结构,选择是否基于初始结构构建复杂的晶体模型,并通过高通量预处理器来收集不同方式构建的多种不同模型,高通量处理器一方面会将所有构型保存在结构数据库中,另一方面会将所有结构向下一步传递,即判定结构是否有效。只有每个点位被完全占据的才可以作为第一性原理计算的有效输入结构,每个原子位点有多个原子分数占据状态的结构仅可以保存在结构数据库中,无法进行进一步计算模拟。获得有效的输入结构后,需要用户选择将要计算的目标工作流,并选择工作流的默认的智能参数配置或者自定义参数配置。进一步,配置完参数后ALKEMIE2.0会通过Socket将多个高通量工作流分配到远程高性能服务器,同时将其保存在工作流数据库中。之后需等待远程任务的计算,并且将每个任务分配到的计算服务器的硬件配置信息保存在工作服务器数据库中。在计算完成或者计算终止之后,自动纠错模块会判断计算结果是否收敛,如果有报错,会根据已经纠错模块已经保存的常见问题及修改策略进一步修改计算参数配置进行重新计算,直到计算结果收敛为止。为了避免陷入死循环的计算过程,在达到最大纠错次数后该任务会被终止并返回计算失败状态。若结果收敛,则会进一步进行数据分析,并将材料性能数据保存在结果数据库中以便数据的重复使用,同时返回计算完成的任务状态。
图4 高通量自动计算与智能纠错流程图
Fig.4 The flowchart of high-throughput automatic calculation and error correction
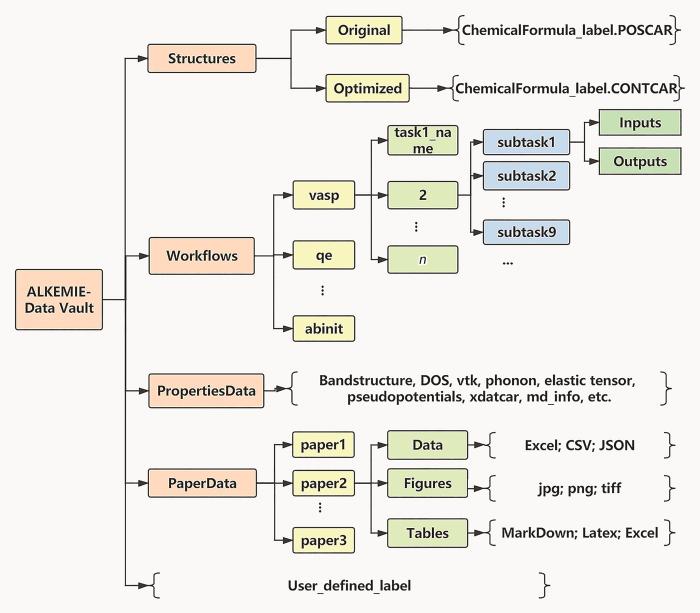
ALKEMIE2.0中所有数据库的集合命名为ALKEMIE-Data Vault,通过数据库API可以实现在ALKEMIE2.0本地软件中的数据可视化,也可以实现数据库在网页中的数据可视化。在用户账号初次创建过程中,ALKEMIE2.0会为每个用户默认配置隐私数据库。进一步,如想实现平台内的数据分享,用户可申请加入ALKEMIE2.0共享数据库以实现数据的社区共享。目前在ALKEMIE2.0社区中,共享数据通过唯一标识符来标明知识产权,数据拥有者的唯一标识为:alkemie.date.classification/user_defined_label.number. 其中alkemie为数据库社区唯一标识;date代表数据创建日期,精确到μs;classification代表数据类别;user_defined_label为用户自定义字段;number为数据唯一索引序号。
隐私数据库和共享数据库的区别主要在于用户查询、读取和保存数据的权限不同,但其都包含相同的子数据库类型和数据键值,如图5所示。每个数据库总体分为4大类型,结构数据库、工作流数据库、性能数据库和论文数据库。其中结构数据库细分为原始结构数据库和经过高精度结构弛豫后的优化数据库;工作流按照计算软件类型不同分为不同的工作流数据库,每个工作流包含对应的子任务流程和每个步骤对应的输入和输出;性能数据库包含若干子数据库,且开发模式中可以根据API进行任意扩展,其主要包含能带数据库、态密度数据库、适用于OpenPhase的VTK数据库、声子谱数据库、弹性张量数据库、赝势数据库、记录计算模拟过程中结构变化过程的XDATCAR数据库、分子动力学中温度能量变化数据库等;论文数据库将论文中的数据库分为数据、图片和表格3大类,根据不同的文件格式可以将数据保存为原始数据和最终发表数据2类。
图5 ALKEMIE2.0数据库类型
Fig.5 The types of databases in ALKEMIE2.0-Data Vault
基于材料数据库,通过人工智能和机器学习方法可以实现新材料的快速设计和材料性能的高效预测。ALKEMIE2.0中人工智能模块为主要集中于Potential Mind AI模块,该模块主要包含以下功能:
(1) 对于任意材料体系,基于已经训练好的模型快速预测该体系未知结构的能量(能量精度与第一性原理计算相当)。
(2) 针对Sb、Te、Sb2Te3 3种材料体系,通过该模块训练产生适用于基于Newton力学的大规模分子动力学模拟的势函数,并通过Atomic Simulation Environments (ASE)开源软件中的分子动力学模块进行微正则系综(NVE)和正则系综(NVT)下的分子动力学模拟。
(4) 构建适用于Mxenes的材料描述符[39]。
(5) 构建可以预测热电材料ZT值和最优载流子浓度的神经网络模型[40]。
ALKEMIE2.0中人工智能模块仍在不断更新和发展中,未来主要研究方向集中于以下方面[41]:
(1) 构建更加高效的材料描述符方法,即如何将三维的材料结构信息解析为有效的机器学习特征值。
(2) 基于微小数据集进行高效的材料性能预测。
(3) 基于主动学习的材料逆向设计(根据性能逆向设计材料结构及成分)。
ALKEMIE2.0的数据库、服务器、内核和可视化模块根据不同的计算服务器和功能类型需求,能以独立模块的方式部署在不同的超算服务器中。目前已经完成了在国家超算天津中心(超大规模)、腾讯云服务器(大规模)、北航超算(一般规模)和用户个人自定义超算(小规模) 4种不同规模的超算服务器上的部署。具体而言,ALKEMIE2.0已将数据库模块、内核模块和可视化模块部署在国家超算天津中心中国材料基因工程高通量计算平台(CNMGE),依靠其强大的计算能力实现更高效的高通量自动计算和云数据存储,而该平台的计算服务器和用户则由CNMGE平台统一管理。ALKEMIE2.0最初架构为客户端-服务端的CS运行模式,但在CNMGE平台中,通过其最新开发的容器技术,用户可用网页浏览器替代客户端的安装,实现通过网页端链接超算进行与客户端完全一致的可视化的高通量自动流程计算;除了在国家级超算部署外,为了实现基于材料基因理念的数据共享和数据高效查询,本团队将ALKEMIE2.0数据库模块和部分用户服务模块部署在了可公开访问的大型企业服务器(腾讯云服务器),以便为用户提供便捷的数据查询功能,但由于腾讯云服务器计算能力和计算成本限制,并未部署高通量计算和可视化模块;ALKEMIE2.0完整功能部署于北京航空航天大学高性能超算集群(BHHPC),该集群以安全、独立和稳定的方式为用户提供可靠的高通量智能计算和数据管理。未来,ALKEMIE2.0将根据战略规划分区域部署在更多的用户个人服务器中(自定义集群)。
ALKEMIE2.0公开发布了完整的用户使用手册和开发手册(
铝被广泛应用于航空、航天及生活的各个领域中,为了获得良好的力学性能和导电性能,在纯Al中合金化不同的固溶元素是常用的方法之一[42,43]。而传统的实验试错方法成本较高,随着计算材料学的发展,通过第一性原理计算模拟初步筛选合金化元素变得至关重要。但是手动计算数十种合金化元素的结构稳定性能、机械性能和导电性能流程繁琐且效率较低,且无法对数据进行高效的分析。因此,本节主要介绍通过高通量自动流程集成计算和数据管理智能平台ALKEMIE2.0,首先从81种二元铝合金中筛选了结构能量稳定的合金化元素,之后通过自动计算其弹性张量筛选了有利于提升纯Al机械性能的合金化元素,最后结合ALKEMIE2.0中BoltzTraP自动工作流[44],计算了二元铝合金的电导率。
纯Al为典型的fcc晶体构型,而Al的合金元素固溶度大多集中于0.1%~1%之间,因此这里构建的初始构型为包含108个原子的3 × 3 × 3的超胞,并将顶点位置的Al原子替换为合金元素,化学表达式为Al107X,X代表合金元素,固溶度为0.92%。本算例中高通量自动流程采用第一性原理计算软件VASP作为基础,在高通量计算过程中的输入参数、K点密度和赝势会根据工作流类别自动进行配置。其中,所有流程K点密度取值为7 × 7 × 7,结构优化采用三步自动优化工作流。第一步,截断能为350 eV,能量收敛标准为1 × 10-4 eV/atom,原子平均受力低于0.05 eV/?;第二步,截断能为520 eV,能量收敛标准为1 × 10-6 eV/atom,原子平均受力低于0.01 eV/?;第三步,截断能为520 eV,能量收敛标准为1 × 10-6 eV/atom,原子平均受力低于0.005 eV/?。结构优化后的Al108晶格常数为12.12 ?,与实验值12.15 ?基本一致。非自洽计算和弹性常数计算工作流截断能均为520 eV。
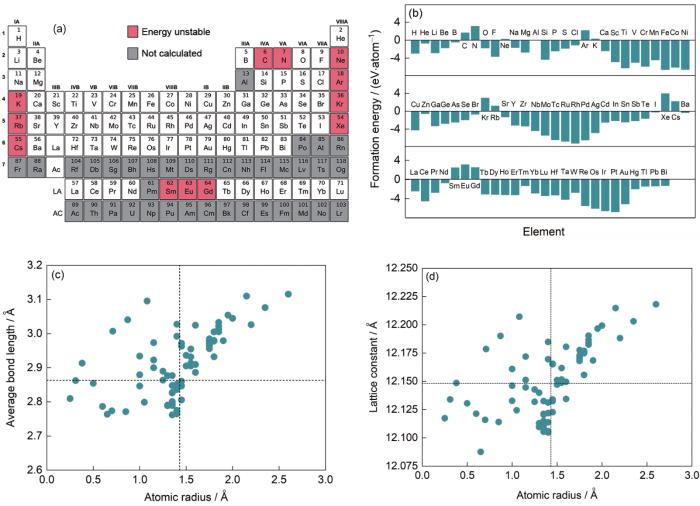
热力学稳定性通常通过形成能判据确定,形成能大于零代表热力学不稳定,反之则代表热力学稳定[45]。高通量自动工作流中形成能的计算方法如
其中,
图6 铝合金热力学稳定性的高通量筛选,包括未计算的合金化元素(灰色)、能量不稳定的合金化元素(红色)以及能量稳定的合金化元素(白色),热力学稳定的合金化元素的形成能(负数代表稳定,正数代表不稳定),及合金元素的平均键长和晶格常数随原子半径的变化散点图
Fig.6 High-throughput screening of the thermodynamic stability of aluminum alloys
(a) illustration of the not calculated elements (gray), the energetically unstable (red), and stable elements (white) in Al, respectively
(b) the formation energy of the 81 alloying element
(c, d) the average bond length (c) and lattice constant (d) of the alloyed compounds (The dashed lines indicate the value of the pure Al)
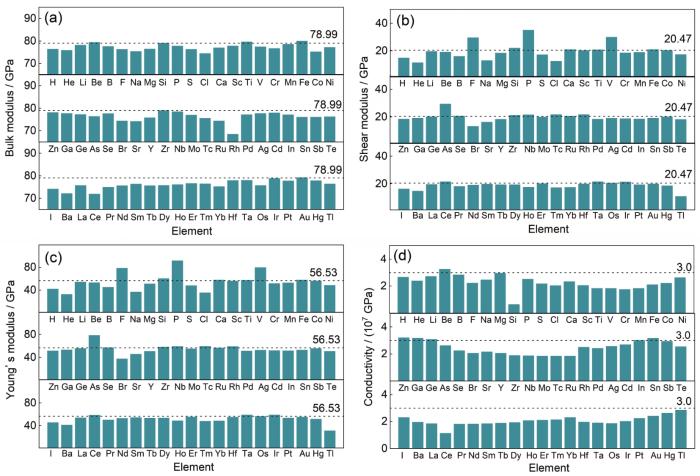
高通量自动工作流中力学性能计算流程包含第一性原理弹性张量计算,Born稳定性判据(Born stability criteria)和基于Voigt-Reuss-Hill近似法则的弹性张量数据分析。首先,通过第一性原理高通量计算获得每个合金元素结构对应的弹性张量矩阵,对于fcc晶体结构,其弹性张量矩阵如
不同合金化元素的体模量如图7a所示,其中,虚线表示离散Fourier变换(DFT)计算获得的纯Al的体模量(78.99 GPa),与实验值(72 GPa[50])基本一致,计算结果表明,Be、Si、Ti、Fe、Ir和Au均可有助于提升Al的体模量以提升铝合金的抗变形能力;不同合金化元素的剪切模量如图7b所示,虚线表示DFT计算获得的纯Al的剪切模量(20.47 GPa),与实验值(25 GPa)基本一致,计算结果表明,F、Si、P、Ca、Ti、V、Fe、Co、As、Se、Zr、Nb、Tc、Ru、Rh、Ce、Ta、Os和Ir合金元素有助于提升Al的剪切模量以提高铝合金抗切应变的能力;不同合金化元素的Young's模量如图7c所示,虚线表示DFT计算获得的纯Al的Young's模量(56.53 GPa),与实验值(70 GPa[51])较为接近,计算结果表明F、Si、P、Ca、Ti、V、Fe、Co、As、Se、Zr、Nb、Tc、Ru、Rh、La、Ta、Os和Ir合金元素有助于提升Al的Young's模量以增强铝合金硬度,提升抗弹性形变的能力。通过力学性能的高通量筛选,Si、Ti、Fe、Ir均可提升二元铝合金的体模量、剪切模量和弹性模量3方面的性能。结合最近研究报道,目前4XXX系Si-Al合金常用于汽车活塞等材料[52],而Fe-Al合金广泛作为空天和汽车工业耐热合金的候选材料[43,53]。
图7 铝合金力学性能和导电性能的高通量筛选
Fig.7 High-throughput screening of mechanical properties and electrical conductivities of aluminum alloys (The dotted line represents the reference value corresponding to pure aluminum calculated by DFT)
(a) bulk modulus (b) shear modulus
(c) Young's modulus (d) conductivity of different alloying elements
本文介绍了作者团队基于自动化、模块化、数据库、智能化和可视化的AMDIV设计理念构建的分布式高通量自动流程集成计算及数据管理智能平台ALKEMIE2.0。该平台主要包含用户界面、计算服务器,材料多类型数据库、高通量自动流程内核和可扩展插件5个核心模块。该平台通过多模块的自由组合实现强大的可移植性,通过插件模块的通用接口实现丰富的可扩展性。进一步而言,高通量自动流程和智能纠错模块使得材料计算模拟复杂的流程更加自动化、智能化,降低了计算模拟过程中出现人为错误的概率;可视化的工作流使得材料计算模拟内部的工作流程更加透明化以提升效率;多类型的材料数据库一方面可以使数据满足FAIR原则,提升数据的可发现性、可获取性、可互操作性和可再利用性;另一方面高质量的材料数据库可以为强大的人工智能算法、深度神经网络和数据挖掘提供数据支持,使得研究人员可以结合结构能量预测、跨尺度势函数、缺陷预测、材料描述符等多个人工智能算法高效预测新材料性能。最后,通过多平台部署和二元铝合金的高通量筛选作为算例验证了ALKEMIE2.0丰富的功能特性。总之,ALKEMIE2.0适用于对材料计算模拟知识掌握程度从初级到专业的所有材料研究人员,为广大科研人员利用数据驱动的材料基因工程设计新材料提供了便捷。ALKEMIE2.0仍在持续开发完善中,未来本团队会将更多精力集中于材料大数据、人工智能算法和跨尺度计算等领域。
 ,1,2
,1,2
1 设计理念与功能架构
1.1 AMDIV设计理念
图1
(1) 自动化
(2) 模块化
(3) 材料数据库
(4) 人工智能
(5) 可视化
1.2 ALKEMIE2.0系统架构
图2

1.3 ALKEMIE2.0平台概况
图3
1.4 ALKEMIE2.0特色功能
2 关键技术
2.1 高通量自动计算流程与智能纠错
图4
2.2 多类型数据库
图5
2.3 人工智能与机器学习
3 高通量筛选与测试应用
3.1 ALKEMIE2.0多平台部署
3.2 高通量筛选在铝合金中的应用
3.2.1 初始构型及参数配置
3.2.2 高通量筛选热力学稳定的合金化元素
图6
3.2.3 二元铝合金力学性能和导电性能的高通量筛选
图7
4 结论
来源--金属学报
 沪公网安备31011202020290号
沪公网安备31011202020290号
